Salzburger Software Modell
Das Salzburger Software Modell versteht sich als Werkzeugkasten für robuste und nachhaltige Webanwendungen. Es besteht aus Prozessen, Hilfsmitteln, Techniken sowie Anleitungen die zu wiederholbarem Erfolg führen.
Nachhaltige Software erfüllt einen bestimmten Zweck und überlebt in chaotischen Umfeldern.
Es erfordert diszipliniertes Vorgehen um dieses erstrebenswerte Ziel zu erreichen. Glück, Zufall und Hoffnung dürfen nichts mit einem erfolgreichen Software Projekte zu tun haben.
Viel Spaß beim stöbern!
Checkliste
Allgemein
- Doppelte Anweisung wird nur einmal verarbeitet
- Daten werden auf Maximalmenge begrenzt
- Fehlende Daten werden gehandhabt
- Definition aller möglichen Parameter
- Definition des gültigen Wertebereichs für jeden Parameter
- Definition aller Geschäftsregeln
- Überschreiben von Daten ist nicht möglich
Benutzeroberfläche
- Template Variablen werden sicher ausgegeben
- Funktioniert auf Desktop-Geräten
- Funktioniert auf Tablet-Geräten
- Funktioniert auf Mobile-Geräten
- Kontrast ist ausreichen
- Bedienbar per Tastatur
- Bedienbar per Screenreader
- Bedienbar ohne JavaScript
- Definition aller Zustände
- Alle Zustände sind erreichbar
- Alle Zustände sind verlassbar
Langlebiger Client
- Aktualisierung per Fernwartung
- Handhabung von Versionskonflikten
- Handhabung von schlechter Internetverbindung
Merkmale von Webanwendungen
Webanwendungen gibt es in allen Farben und Formen. Diese Vielfältigkeit ermöglicht es auf den unterschiedlichsten Ebenen darüber zu sprechen. Das ist eine Herausforderung in der Kommunikation. Die Vielfältigkeit verleitet dazu in die Tiefe zu gehen. In vielen Situationen ist ein hoher Detailgrad jedoch hinderlich.
Für solche Situationen ist die Liste von Merkmalen gedacht. Sie ermöglicht es Software zu charakterisieren ohne dabei ins Detail zu gehen. Zum Beispiel wird die Planung beschleunigt durch das frühzeitige Sichtbarmachen von Komplexität.
Die Merkmale sind auch in der Implementierung nützlich. Sie sind ein guter Einstiegspunkt für Fragen zur Implementierung. Ebenso sind sie als Gedankenstütze und Referenzdokument geeignet.
Abfrage
Macht Informationen für Benutzeroberflächen und Schnittstellen zugänglich.
Beispiel: Kunden und Kundinnen die offene Rechnungen haben.
Checkliste
- Ist die Idempotenz gewährleistet?
- Wird die Datenmenge limitiert?
- Wird ein externer Dienst verwendet?
- Wird eine Volltextsuche verwendet?
- Wird eine Facetten-Navigation verwendet?
- Ist eine Authentifizierung nötig?
- Ist eine Zugriffskontrolle nötig?
Anweisung
Stößt eine Funktion oder größeren Prozess an. Kann synchron oder asynchron verarbeitet werden.
Beispiel: Stellenangebot sichtbar schalten.
Checkliste
- Ist die Idempotenz gewährleistet?
- Welche Daten sind für die Durchführung nötig?
- Bei welchen Daten handelt es sich um Benutzereingaben?
- Welche Geschäftsregeln sind einzuhalten?
- Kommt es zu einer Hintergrundverarbeitung?
- Ist eine Authentifizierung nötig?
- Ist eine Zugriffskontrolle nötig?
- Wird gegen klassische Angriffsvektoren geschützt?
Benutzereingaben
Daten die von BenutzerInnen stammen. Werden meist über ein Formular erfasst.
Beispiel: Leistungsbeschreibung bei der Angebotsstellung.
Checkliste
- Wie werden die Daten validiert?
- Wird gegen klassische Angriffsvektoren geschützt?
- Sind Videos inkludiert?
- Sind Bilder inkludiert?
- Sind sonstige Dateien inkludiert?
Benutzeroberfläche
Ermöglicht Menschen mit der Software zu interagieren.
Beispiel: Übersicht aller erhaltenen Bestellungen.
Checkliste
- Funktioniert es auf Desktop-Geräten?
- Funktioniert es auf Tablet-Geräten?
- Funktioniert es auf Mobile-Geräten?
- Ist es barrierefrei?
- Funktioniert es ohne JavaScript?
Langlebiger Client
Je nach Implementierung kann die Benutzeroberfläche lange in Betrieb sein. Typische Beispiele sind Single-Page-Webanwendung.
Beispiel: Mobile Anwendung die Offline fähig ist.
Checkliste
- Wie werden Versionskonflikte in der Schnittstelle zwischen Client und Server gehandhabt?
- Ist ein Schutz gegen Gleichzeitigkeit gewährleistet?
- Ist ein Schutz gegen Fehlerszenarien eines externen Dienstes gewährleistet?
- Wie kann der Client per Fernwartung aktualisiert werden?
Schnittstelle
Ermöglicht externen Systemen mit der Software zu interagieren.
Beispiel: Einspielen von Stellenangeboten aus SAP.
Checkliste
- Ist eine Authentifizierung nötig?
- Ist eine Zugriffskontrolle nötig?
- Welches Format wird verwendet?
- Wie wird das Schema dokumentiert?
- Wie wird die Verwendung dokumentiert?
- Wie wird Versionierung gehandhabt?
Authentifizierung
Teile der Software sind nur verwendbar nachdem sich Mensch oder Maschine erfolgreich authentifiziert haben.
Beispiel: Jobbörsen Verwaltungsbereich ist nur mit erfolgreicher Authentifizierung zugänglich.
Checkliste
- Wird die Authentifizierung innerhalb der Software vorgenommen?
- Ist eine Zwei-Faktor-Authentifizierung angebracht?
- Wie kann eine Authentifizierung entzogen werden?
- Wer kann sich authentifizieren?
Zugriffskontrolle
Der Zugriff auf Anweisungen und Abfragen wird individuell kontrolliert.
Beispiel: Die Buchhaltung kann Rechnungen sehen jedoch nicht stellen.
Checkliste
- Setzt eine Authentifizierung voraus.
- Wie werden die Berechtigungen kontrolliert?
- Wie sieht das Berechtigungsmodell aus?
Mandantenfähigkeit
Die selbe Instanz der Software bedient multiple, voneinander unabhängige, Mandanten. Mandanten haben nur Einsicht in ihre eigenen Daten. Nicht zu verwechseln mit Mehrfachsitzungen.
Beispiel: Shopify wird für unterschiedliche Online-Shops genutzt.
Checkliste
- Wie werden die Daten zwischen Mandanten getrennt?
- Gibt es Basisdaten auf die alle Mandanten zurückgreifen?
- Sind getrennte Backups nötig?
- Wie werden Mandanten hinzugefügt?
- Wie werden Mandanten entfernt?
Mehrfachsitzungen
Multiple Menschen oder Maschinen interagieren mit der Software gleichzeitig.
Beispiel: Zwei BuchhalterInnen sind für die Rechnungsstellung verantwortlich.
Checkliste
- Wie wird das überschreiben von Daten verhindert?
Asynchrone Anweisung
Asynchrone Anweisungen werden im Hintergrund verarbeitet. Das wird genutzt um rechenintensive Aufgaben im Hintergrund zu erledigen ohne die Rückmeldung an BenutzerInnen zu verzögern.
Beispiel: Versand von Emails.
Checkliste
- Ist die Idempotenz gewährleistet?
- Kann die Hintergrundverarbeitung aus der Benutzeroberfläche angestoßen werden?
- Ist der Status einer Hintergrundverarbeitung in der Benutzeroberfläche einsehbar?
- Wie wird ein Fehler gehandhabt?
- Wie wird der Zustand persistiert?
- Ist das transaktionale Anstoßen gewährleistet?
Terminierte Anweisung
Eine Anweisung wird zu einem Zeitpunkt in der Zukunft ohne Benutzerinteraktion gegeben.
Beispiel: Stellenangebot 30 Tage nach dem sichtbar schalten automatisch verbergen.
Checkliste
- Sind die terminierten Anweisungen in der Benutzeroberfläche sichtbar?
- Kann die Anweisung manuell von der Benutzeroberfläche gegeben werden?
Zeit
Zeitangaben werden gespeichert und verarbeitet.
Beispiel: Stellenangebote sind nur in einem bestimmten Zeitraum sichtbar.
Checkliste
- Ist es nötig Zeitzonen zu berücksichtigen?
- Werden Zeitangaben einheitlich persistiert?
Geld
Es gibt Berechnungen mit Geldsummen.
Beispiel: Anmeldung zu mehreren Turnieren mit unterschiedlichen Startgebühren.
Checkliste
- Ist das Konzept Geld als Value Object implementiert?
- Sind mehrere Währungen zu berücksichtigen?
- Wird zwischen Währungen gewechselt?
PDF Erstellung
Zur Laufzeit erstellte PDF Dateien.
Beispiel: Angebot kann als PDF heruntergeladen werden.
Checkliste
- Kann eine Vorschau angezeigt werden?
- Werden Benutzereingaben formatiert dargestellt?
- Wird das PDF bei Bedarf erstellt oder persistiert?
- Findet die Erstellung im Hintergrund statt?
Import von Daten
Große Mengen an Daten werden in einem einzigen Arbeitsschritt importiert.
Beispiel: Verkaufszahlen werden aus einem Excelsheet importiert.
Checkliste
- Um welche Datenmengen handelt es sich?
- Wie oft werden Daten importiert?
- Wie werden die Daten validiert?
- Welche Formate werden unterstützt?
- Findet der Import im Hintergrund statt?
Export von Daten
Daten werden für eine externe Weiterverwendung exportiet.
Beispiel: Prozess Statistiken werden als Excelsheet exportiert.
Checkliste
- Um welche Datenmengen handelt es sich?
- Wie oft werden Daten exportiert?
- Welche Formate werden unterstützt?
- Findet der Export im Hintergrund statt?
Externer Dienst
Gewisse Aufgaben werden an Dritte ausgelagert. Strenggenommen zählt dazu auch der Datenbankserver.
Beispiel: Email Versand wird von einem Dienstleister übernommen um bessere Zustellraten zu erreichen.
Checkliste
- Wird dieser externe Dienst wirklich benötigt?
- Wie wirkt sich eine Verschlechterung des externen Dienstes aus?
- Wie wirkt sich ein Ausfall des externen Dienstes aus?
- Wie wirkt sich eine Stilllegung des externen Dienstes aus?
- Werden personenbezogene Daten übermittelt?
- Unterstützt der externe Dienst Idempotenz?
- Sind die Kompetenzen für Betrieb & Wartung vorhanden?
Personenbezogene Daten
Es werden personenbezogene Daten gespeichert und verarbeitet.
Beispiel: Kundenportal mit Email und Passwort Zugang.
Checkliste
- Welche personenbezogene Daten werden erfasst?
- Wie werden die Betroffenen Rechte gehandhabt?
- Wie werden die Einwilligungen eingeholt?
- Wie werden die Einwilligungen persistiert?
- Welche externen Dienste verarbeiten personenbezogene Daten?
Online Bezahlung
BenutzerInnen können selbstständig Online bezahlen und Zahlungsstatus wird automatisch erfasst.
Beispiel: Unternehmen können Stellenangebote direkt auf der Jobbörse bezahlen.
Checkliste
- Welche Zahlungsmethoden werden verwendet?
- Welcher externe Dienst wird verwendet?
- Welche personenbezogene Daten werden erfasst?
- Werden Berechnungen von Geldsummen durchgeführt?
Email Versand
Transaktionale Emails die über individuelle Vorkommnisse informieren.
Beispiel: Bestellbestätigung über den gerade getätigten Einkauf.
Checkliste
- Wie wird eine fehlgeschlagene Zustellung gehandhabt?
- Wird eine HTML-Email benötigt?
- Gibt es eine Klartext Version von HTML-Emails?
- Ist die Idempotenz gewährleistet?
- Kann eine Vorschau angezeigt werden?
- Findet der Versand im Hintergrund statt?
- Welche personenbezogene Daten werden erfasst?
- Welcher externer Dienst wird verwendet?
Newsletter Versand
Transaktionale Emails die über allgemeine Vorkommnisse informieren.
Beispiel: Ankündigung eines neuen Produktes.
Checkliste
- Wie wird eine fehlgeschlagene Zustellung gehandhabt?
- Wird eine HTML-Email benötigt?
- Gibt es eine Klartext Version von HTML-Emails?
- Ist die Idempotenz gewährleistet?
- Kann eine Vorschau angezeigt werden?
- Findet der Versand im Hintergrund statt?
- Ist ein Probeversand möglich?
- Welche personenbezogene Daten werden erfasst?
- Welcher externer Dienst wird verwendet?
Mehrsprachigkeit
BenutzerInnen können die Software in verschiedenen Sprachen verwenden.
Beispiel: Unternehmen expandiert und baut einen zweiten Standort im Ausland auf.
Checkliste
- Welche Sprachen sind verfügbar?
- Wie werden Übersetzungen aktuell gehalten?
- Werden Sprachen benötigt wo sich die Darstellung verändert?
- Wie wird es in der Benutzeroberfläche gehandhabt?
- Wie wird es in Emails gehandhabt?
- Wie wird es in Newslettern gehandhabt?
Implementierung
Idempotenz
Eine idempotente Abfrage verändert keine Daten. Jede Abfrage sollte idempotent sein. Wenn das nicht möglich ist handelt es sich wahrscheinlich um keine Abfrage sondern eine Anweisung.
Eine Anweisung führt in der Regel zu veränderten Daten. Die Veränderungen finden unter Umständen nicht nur innerhalb der Software sondern auch bei externen Diensten statt. Im Gegensatz zu Abfragen bedeutet es bei Anweisungen etwas anderes wenn von Idempotenz gesprochen wird.
Eine Anweisung führt natürlich zu Veränderung, aber nur beim ersten Mal. Wenn die selbe Anweisung mehrfach entgegen genommen wird hat nur die erste Auswirkungen.
Diese Eigenschaft ist in der Praxis für robuste Systeme sehr nützlich. Bei einem Implementierungsfehler wodurch eine Anweisung mehrfach ausgeführt wird entsteht kein Schaden. In einer Situation mit schlechter Netzwerkverbindung können Anweisungen erneut gesendet werden. Das passiert zum Beispiel auch automatisch durch einen Webbrowser. Diese Wiederholung von HTTP-Requests führt ohne idempotente Anweisungen zu Problemen.
Implementierung
Folgender Ansatz funktioniert nur wenn eine einzige, ACID kompatible, Datenspeicher verwendet wird und es zu keinen sonstigen Datenveränderungen in externen Diensten kommt. Wenn diese Voraussetzungen nicht gegeben sind muss mit einem individuellen Wiederherstellungs-Prozess gearbeitet werden.
In einer Situation mit den beschriebenen Voraussetzungen ist der erste Schritt das garantieren einer sequenziellen Abarbeitung von identischen Anweisungen.
In PostgreSQL kann das mit dem Isolations Level Serializable von Transaktionen erreicht werden.
(Relevante Dokumentation von PostgreSQL.)
Der zweite Schritt ist das erkennen dass eine Anweisung bereits ausgeführt wurde. In diesem Fall wird das ausführen der Anweisung übersprüngen und stattdessen sofort die Erfolgsantwort zurückgegeben.
Im folgenden Beispiel ist Pseudoquellcode für einen fiktiven HTTP-Endpunkt zur Registrierung eines Accounts zu sehen.
post '/accounts' do |request|
email = request.parameters.fetch(:email)
DB.transaction(isolation: :serializable) do
account = Account.find_by(email: email)
if account.exists?
return successful_account_registration(account)
else
account = Account.create(email: email)
return successful_account_registration(account)
end
end
end
Literatur
Angriffsvektoren
Eine Software die im Internet erreichbar ist muss gegen zufällige und gezielte Angriffe geschützt werden. Es ist zu empfehlen davon auszugehen das auch interne Netzwerke kompromitiert werden können. In diesem Fall muss jede Art von Software entsprechend geschützt werden.
Als Startpunkt ist die OWASP Top 10 Liste an Angriffsvektoren geeignet.
Literaturverzeichnis
Vorschau von Dokumenten
Bei Dokumenten wie Emails und PDFs ist es empfehlenswert eine Implementierung zu wählen mit der unkomplizierte Vorschau Dokumente generiert werden können.
Um das zu erreichen muss eine Entkopplung von Frameworks und Bibliotheken erreicht werden die nicht zwingend nötig sind. Im Idealfall werden nur primitive Daten übergeben um das entsprechende Dokumente zu generieren.
Dieses Vorgehen verkürzt die Feedbackschleife in der Implementierung erheblich. Unterschiedliche Szenarien und Versionen des Dokuments können mit niedrigen Kosten erstellt werden.
Außerdem erleichtert dieser Ansatz die Entwicklung von Vorschau Funktionalität gegenüber BenutzerInnen.
Volltextsuche
Ist die PostgreSQL Volltextsuche ausreichend oder muss wirklich ein zusätzlicher externer Dienst verwendet werden?
Facetten Navigation
Möglichst schnell einen Prototypen bauen um herausfinden was benötigt wird und wie es am besten funktioniert.
- Welche Facetten gibt es?
- Wie sehen die Facetten Optionen aus?
- Können mehrere Facetten aktiv sein?
- Können mehrere Optionen einer Facette aktiv sein?
Transaktionale Hintergrundprozesse
Hintergrundprozesse die auf einem externen, zweiten Datenspeicher, aufbauen müssen nach einem bestimmten Schema implementiert sein um Robustheit zu erlangen.
Wenn die Zeile queue_job(stuff) in folgendem Beispiel direkt in den zweiten Datenspeicher schreibt gibt es ein Problem. Wenn Sidekiq wie empfohlen verwendet wird ist die Problematik immer da.
DB.transaction do
stuff = do_and_save_stuff_to_database
queue_job(stuff)
do_other_stuff
end
Was ist das Problem?
Es könnte in do_other_stuff zu einem Fehler kommen der die Transaktion abbricht. In diesem Fall gibt es einen Hintergrundprozess der sich auf nicht vorhandene Daten bezieht.
Alternativ könnte der Hintergrundprozess sofort abgearbeitet werden bevor die Daten in den primären Datenspeicher geschrieben wurden.
Wenn der Hintergrundprozess nach der Transaktion angestoßen wird gibt es ein weiteres Fehlerszenario. Die Transaktion schreibt Daten in den primären Datenspeicher um dann später zu merken dass der Hintergrundprozess nicht angestoßen werden konnte.
Alle diese Situation sind nicht wünschenswert. Eine mögliche Lösung wird in Transactionally Staged Job Drains in Postgres aufgezeigt.
Literaturverzeichnis
Gleichzeitigkeit
Mit Mehrfachsitzungen kann es zu Situationen kommen wo Anweisungen gleichzeitig ausgeführt werden. Wenn sich diese Anweisungen gegenseitig beeinflussen kommt es im schlimmsten Fall zu einem Datenverlust der nicht bemerkt wird.
Im Idealfall sendet deshalb jede Anweisung eine Version mit, auf der sie basiert. Das ermöglicht überschneidende Anweisungen zu entdecken und darauf zu reagieren.
Fehler Szenarien
HTTP Retry
Wenn ein Webbrowser keine Antwort auf einen HTTP-Request bekommt weil zum Beispiel die Verbindung unterbrochen wurde wiederholt er automatisch den HTTP-Request.
Dieses Verhalten ist für die BenutzerInnen nicht bemerkbar.
Aus diversen Gründen werden auch POST und PUT HTTP-Requests wiederholt.
Was wiederum zu Problemen und inkonsistenten Daten führen kann.
The status quo, therefore, is that no Web application can read HTTP’s retry requirements as a guarantee that any given request won’t be retried, even for methods that are not idempotent. As a result, applications that care about avoiding duplicate requests need to build a way to detect not only user retries but also automatic retries into the application “above” HTTP itself. https://mnot.github.io/I-D/Abandoned/httpbis-retry/#auto_retry
In der Praxis müssen demnach auch POST und PUT HTTP-Endpunkte idempotent sein.
Details dazu sind unter Implementierung von Idempotentz zu finden.
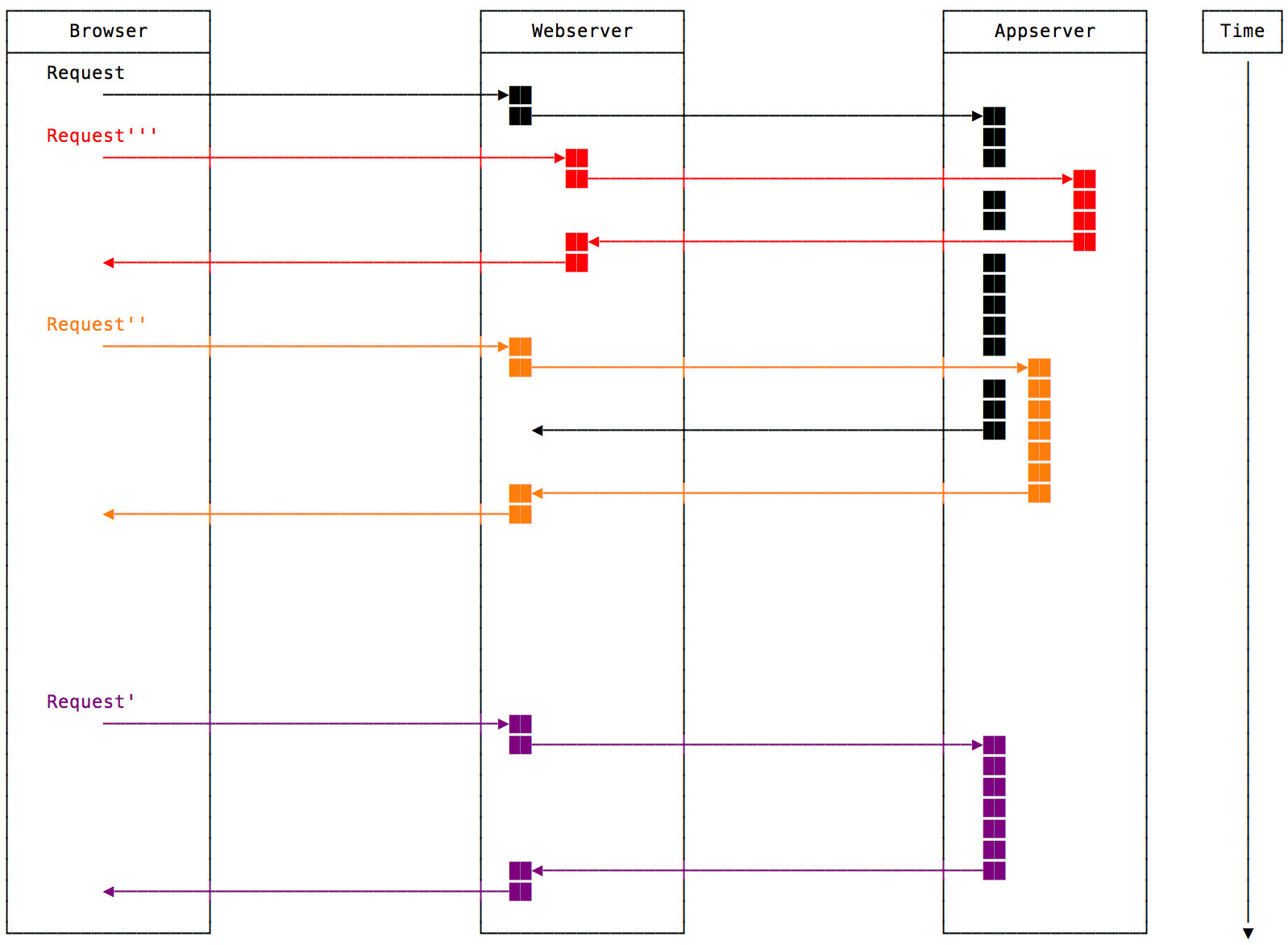
Die Implementierung für HTTP-Endpunkte ist identisch zu sonstigen idempotenten Anweisungen. Wie in der folgenden Visualisierung zu sehen ist gibt es drei verschiedene Szenarien.
-
Der Original HTTP-Request (
Request) wird von der Software vollständig abgearbeitet bevor der Retry HTTP-Request (Request') ankommt. -
Der Retry HTTP-Request (
Request'') kommt an bevor die Verarbeitung des Originals abgeschlossen ist. Die Verarbeitung des Originals ist jedoch schneller. -
Der Retry HTTP-Request (
Request''') kommt an bevor die Verarbeitung des Originals abgeschlossen ist. Die Verarbeitung des Originals ist jedoch langsamer.