HTTP Retry
Wenn ein Webbrowser keine Antwort auf einen HTTP-Request bekommt weil zum Beispiel die Verbindung unterbrochen wurde wiederholt er automatisch den HTTP-Request.
Dieses Verhalten ist für die BenutzerInnen nicht bemerkbar.
Aus diversen Gründen werden auch POST und PUT HTTP-Requests wiederholt.
Was wiederum zu Problemen und inkonsistenten Daten führen kann.
The status quo, therefore, is that no Web application can read HTTP’s retry requirements as a guarantee that any given request won’t be retried, even for methods that are not idempotent. As a result, applications that care about avoiding duplicate requests need to build a way to detect not only user retries but also automatic retries into the application “above” HTTP itself. https://mnot.github.io/I-D/Abandoned/httpbis-retry/#auto_retry
In der Praxis müssen demnach auch POST und PUT HTTP-Endpunkte idempotent sein.
Details dazu sind unter Implementierung von Idempotentz zu finden.
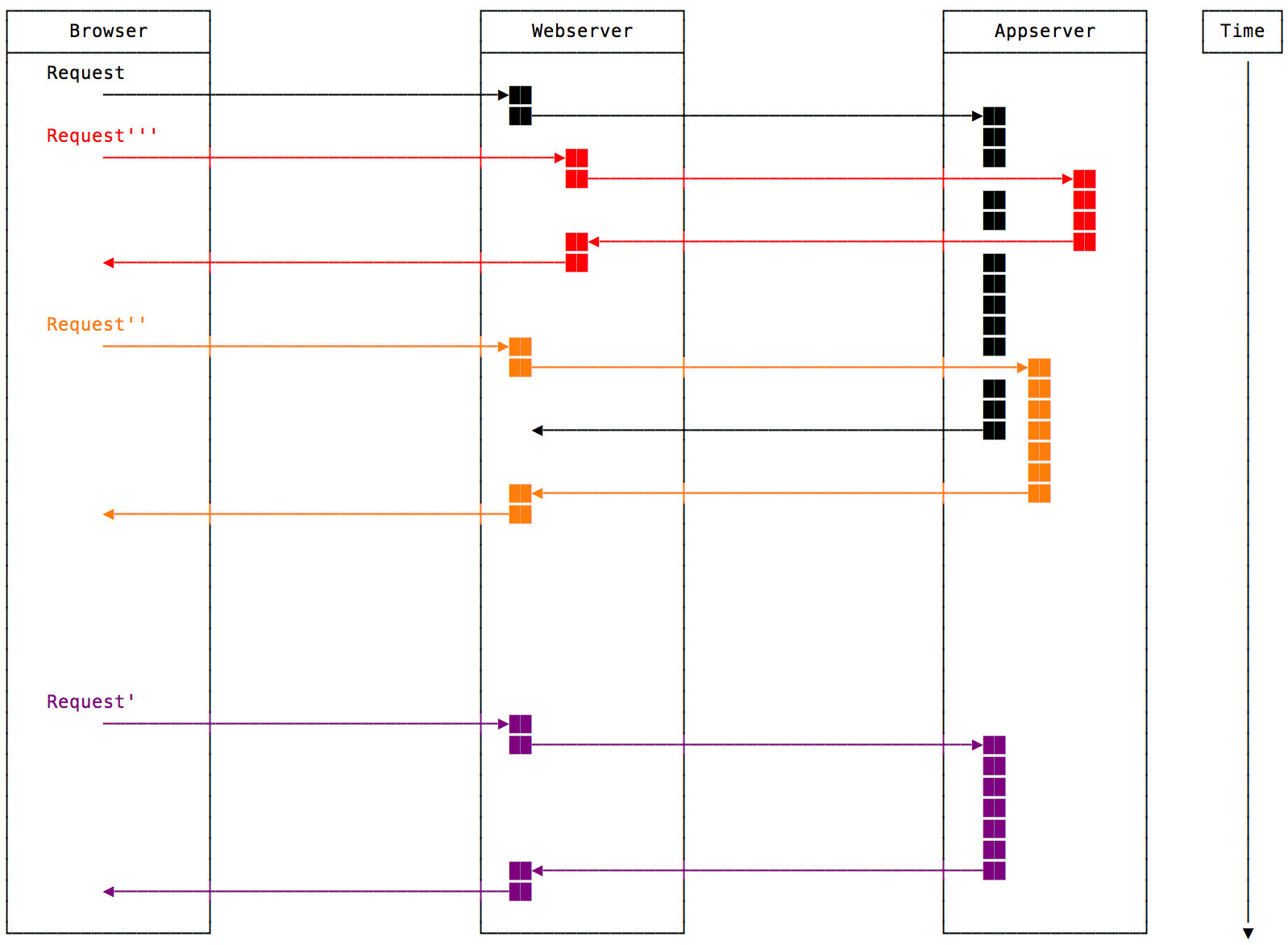
Die Implementierung für HTTP-Endpunkte ist identisch zu sonstigen idempotenten Anweisungen. Wie in der folgenden Visualisierung zu sehen ist gibt es drei verschiedene Szenarien.
-
Der Original HTTP-Request (
Request) wird von der Software vollständig abgearbeitet bevor der Retry HTTP-Request (Request') ankommt. -
Der Retry HTTP-Request (
Request'') kommt an bevor die Verarbeitung des Originals abgeschlossen ist. Die Verarbeitung des Originals ist jedoch schneller. -
Der Retry HTTP-Request (
Request''') kommt an bevor die Verarbeitung des Originals abgeschlossen ist. Die Verarbeitung des Originals ist jedoch langsamer.